Memory Management in Linux Kernel
Introduction #
When we say Memory Management in Linux Kernel, there are two parts to it. You have one set of memory management files inside respective architecture folders (low level mm) and one on the top of linux kernel (high level mm).
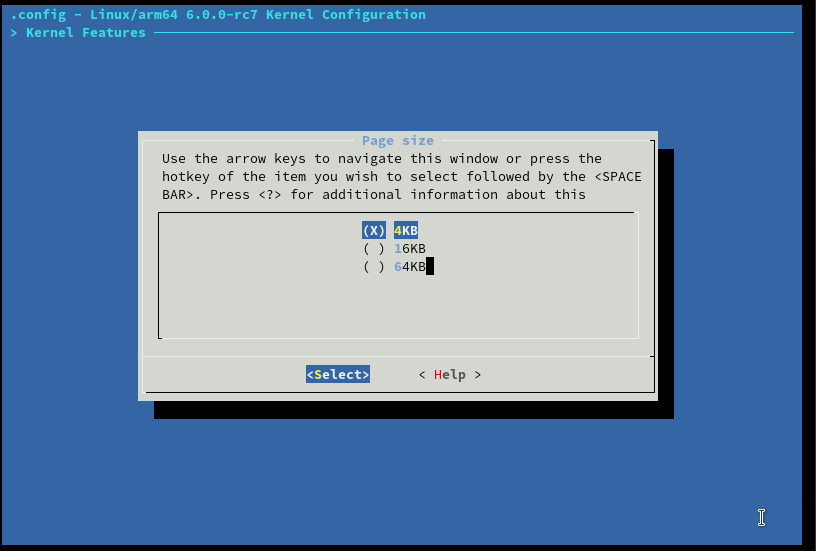
Then ones inside the arch specific folders are memory initializers, these are processor dependent and mm folder at the root of the kernel is the memory manager which is processor independent. If we take a look inside arch/arm64/mm/init.c, we can see that allocations of zones which we will look into a bit later and mapping of physical memory is done here. The memory initializer sets up the framework for memory manager to use the memory. Before boot the view of memory is that of an array, after the memory initialization the view of memory is that of pages to the system. One thing to note about setting up pages during the initalization is the size of pages. By default on most system the page size is 4KB, but in certain architectures like arm64 we have the option to set the default page size to 4KB or 16KB or 64KB. This can be set during the kernel compilation phase using ’’’ make ARCH=arm64 menuconfig’’’ and navigatint to Kernel Features followed by Page Size.
Linux supports normal size page and huge pages(Will talk about huge page later in the post).
Once we are into the protected mode of processors view, we see the memory as a frames. To access the physical memory from the frame, we jump to the frame and use and offset to access the required physical address. So Physical Address = Frame no + offset.
Lets say we have a ram of 4GB each fram size is 4KB, so the total number of frames is going to be 4GB/4KB = 1000000 number of frames.
Lets try to see the number of page descriptors in our system:
#include <linux/module.h>
#include <linux/mm.h>
#include <linux/slab.h>
int init_module(void){
unsigned char *ptr;
unsigned char *phy_addr;
pr_info("%s: Size of struct page in bytes = %ld\n", __func__, sizeof(struct page));
pr_info("%s: Total number of pages = %ld\n", __func__, get_num_physpages());
ptr = kmalloc(4096, GFP_KERNEL);
pr_info("%s, Value of ptr = %p\n", __func__, ptr);
phy_addr = (unsigned char*)__pa(ptr);
pr_info("%s: The Physical Address is = %p\n", __func__, phy_addr);
strcpy(ptr,"Writing data to page\n");
kfree(ptr);
return 0;
}
void exit_module(void){
}
So we can see the following output on demsg on my system:

I have 8GB of ram on my system, with a default configuration of 4KB pages. So total number of pages- page descriptors will be equal to 8GB/4KB = ~2000000 number of page descriptors and thats what we see in the output of the program as well.
So is it mandatory that the frame sizes should be 4KB only? No, in case we have variable frame sizes we call them as segmented memory And in case we have all frames with equal size then we call them as paged memory. This can be done while configuring the MMU. Linux across architecure uses paging.
The transition from the array view to page view is taken care by the low level mm. Low level mm for each frame creates structure to represent the same view to software, creates page descriptors. This page descriptors representes a frame. So in our case above of having 4GB of RAM with 1000000 number of frames, we would have 1000000 page descriptors, each representing a frame.
One thing not to get confused here is that the page sizes are of 4KB but the page descriptors are NOT 4KB in size. Page to frame mappings are 1-to-1, but the mappings are not static. Since the mapping is dynamic, there needs to be tracking of which descriptors are pointing to which frames. This is done by Page Frame Table structure, which stores information on which page descriptor points to which frame.
The responsibilites of low level mmu are:
- Initialize MMU (Page view).
- Populate the required structures - Page Tables
- Categorize pages into zones.
- Initialize the buddy system(low level memory allocator).
- Finally call one of page allocators in high level mm.
Okay what are these zone? Earlier when we saw contents of arch/arm64/mm/init.c you have references to zones.
There are two different zoning polocies, depending on 32 or 64-bit machines.
On 32-bit machines (where max if 4GB RAM), 1GB is used by the kernel and 3GB used in userspace. Within the 1GB of address, 0 to 16MB is Zone DMA, 16 to 896MB is Zone Normal. Above 896MB is High mem zone. Pages in High mem zone are not permanently mapped. High mem zone is used when kernel needs to access some part of user space, the required memory is temporarily mapped for kernel use. Kernel here cannot use beyond 1GB of physical memory.
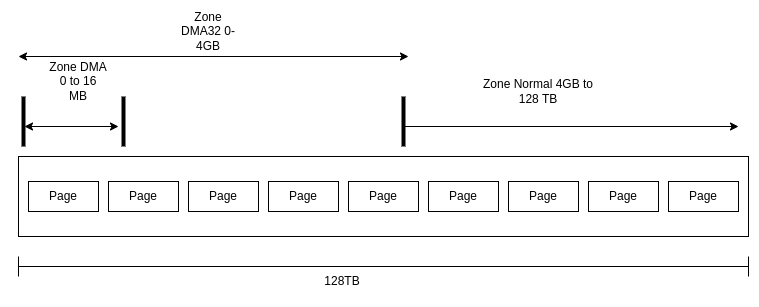
On 64-bit machines, the virtual address is of 48bits so thats 256TB of address space is possible. The split for kernel and user space here is 128TB for each. Whatever user can map, kernel can also map. The zone split for 64-bit machines is 0-16 as Zone DMA which is not much used. 2nd Zone being Zone DMA32 0-4GB (Zone DMA and Zone DMA32 overlap). Beyond 4GB whatever is availabe in RAM is Normal Zone. There is no High Mem zone on 64-bit platform.
So one way to take a look at the total kernel virtual address space size is using the kcore under proc file system.
ls -lh /proc/kcore on 64-bit machine show use the size to be 128TB and 1GB for 32-bit machines



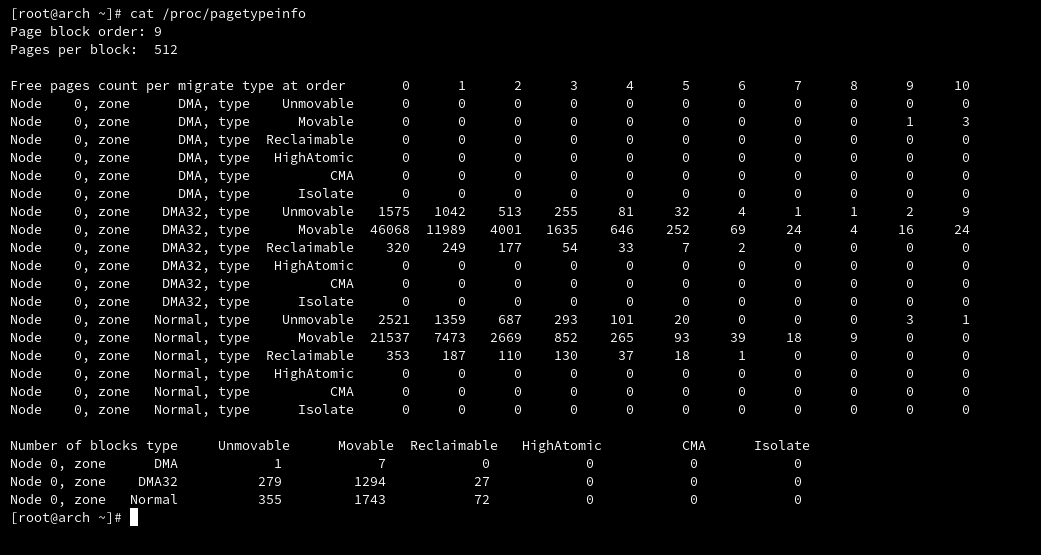
I have a 64-bit machine and the following command shows the zones on my machine: cat /proc/pagetypeinfo. We have DMA, DMA32 and Normal zones.
I had a 32-bit virtual machine booted up to see the details of pagetypeinfo, here you can see the difference in the zones - You have DMA, Normal and High Mem zone.
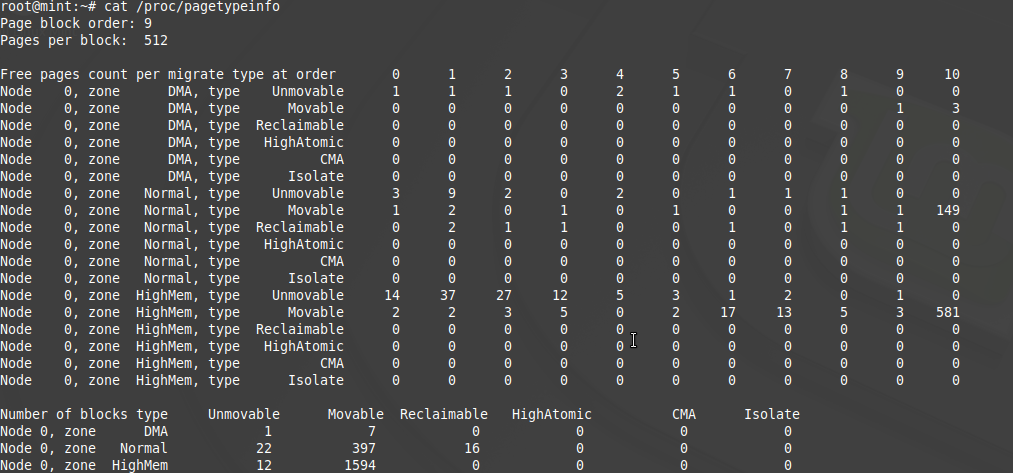
From kernel documentation - The pagetypinfo begins with information on the size of a page block. It then gives the same type of information as buddyinfo except broken down by migrate-type and finishes with details on how many page blocks of each type exist. In the case of Unified memory architecture we have one node - Node 0 covering all zones. In case of NUMA we would have multiple Nodes for each of the zones.
numactl command give more information on nodes and node binding in NUMA machines.
In case of NUMA machines pg_data_t structure for each node would describe the memory layout, on UMA machines a single pglist_data describes the whole memory. Most of what I use are UMA machines and taking a look at struct pglist_data we have an array of zones called node_zones of struct zone. This struct zone has an array called __watermark, with enums zone_watermarks like WMARK_MIN, WMARK_LOW, WMARK_HIGH, WMARK_PROMO and NR_WMARK. These watermarks are for identification by GFP flags The kernel uses kmap_atomic to map pages to zone high mem in 32-bit machines.
One other command that gives detailed info on these zones is cat /proc/zoneinfo
The DMA zone is used for allocating DMA mappings by any driver, there are legacy x86 DMA engines, to support those we these DMA zones. Normal zone is where kernel can map and get VA without having to do complex page operations.
Now since we have understood what zones are and how memory is located, earlier in this post we wrote a program to count the total number of pages/page descriptors on our system.Lets try to understand what we are doing in that program.
We are using mm.h header file to make use of memory subsystems key macros. We are using slab.h to allocate 1 page of memory. we are using sizeof to print the size of page struct. Note that this is not the size of a page in memory, this is size of structure which holds the info about the page in memory and from out program we see that the size of struct page is 64 bytes. get_num_physpages() returns the number of pages which should match with the configuration of the system.
Ownership of a page implies ownership of a frame. kmalloc function return the page descriptor + offset and not frame + offset. The frame is abstracted, its only a page view. If a frame size is 4k. minimum of 12bits would be required to point to a location within the frame. The other bits indicate the page identifier to frame identifier.
Page Allocation #
The memory manager has multiple allocators like Page, Slab, Cache, Fragment. Reason for these allocators for varied type of allocators. All these are just front ends and the backend is the low level memory manager.
Page allocator is the base allocator for all other allocators and interfaces with the zone manager. Slab, Cache, Fragment are built on to of page allocator. What ever page allocator returns is physically contigious block. If page allocator cannot find physically contigious block it returns failure.
There are 4 functions that we can use to acquire pages:
- alloc_page
- alloc_pages
- __get_free_page
- __get_free_pages
alloc_page apis returns the address of page descriptors. Whereas __get_free_page apis returns you the Virtual address. __get_free_page api is a wrapper around alloc_page with additional step of page_address api.
Lets take a look a program where we try to get a page:
#include <linux/module.h>
#include <linux/mm.h>
#include <linux/slab.h>
#include <linux/gfp.h>
int init_module(void){
struct page *pg;
char *ptr;
pg = alloc_page(GFP_KERNEL); //Returns the address of page descriptor
if(!pg){
return -1;
}
ptr = page_address(pg); //Looks up in page descriptor and returns the VA
pr_info("%s: Page Address: %p\n",__func__, pg);
pr_info("%s: Frame Number: %ld\n",__func__, page_to_pfn(pg));
pr_info("%s: Page Number: %p\n",__func__, pfn_to_page(page_to_pfn(pg)));
strcpy(ptr, "Writing to page\n");
pr_info("%s: Reading from %p: %s\n",__func__, pg, ptr);
free_page((unsigned long)ptr); //Page will go back to free pool
return 0;
}
void exit_module(void){
}
The second api that we can use to acquire pages is alloc_pages, alloc_pages has another argument called order where we can specify the order of size of page that we need. Similarly we have __get_free_pages where we mention the page size in order of 2.